Snowpark ML Model Registryから最新バージョンのモデルを利用する
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
データ事業本部 機械学習チームの鈴木です。
Snowpark MLのModel Registryは、Modeling APIで作成した機械学習モデルを登録し、PythonおよびSQLで呼び出して使うことができます。
モデルはバージョン管理を行うことができ、特定のバージョンおよびエイリアスでどのバージョンを使うか指定できます。
今回は最新バージョンのモデルを利用するケースを想定して、エイリアスの使い方をご紹介します。
Model Registryについて
Model RegistryはSnowpark MLにおけるMLOps向けの機能の一つで、Snowflakeで機械学習モデルとそのメタデータを安全に管理することができます。
登録したモデルはバージョン管理を行うことができ、特定のバージョンおよびエイリアスで指定しPythonおよびSQLで呼び出して推論に使うことができます。
モデルとしてPipelineも登録でき、前処理も含めて管理できる点で非常に使いやすい機能です。
過去に以下の記事で紹介しています。
モデルのバージョンとエイリアス
log_modelメソッドによりModel Registryに登録する際に、バージョン名を指定することができます。
# 以下ガイドより2024/10/26に引用
# https://docs.snowflake.com/developer-guide/snowflake-ml/model-registry/overview#registering-models-and-versions
mv = reg.log_model(clf,
model_name="my_model",
version_name="v1",
conda_dependencies=["scikit-learn"],
comment="My awesome ML model",
metrics={"score": 96},
sample_input_data=train_features,
task=type_hints.Task.TABULAR_BINARY_CLASSIFICATION)
モデルを呼び出す際は、モデルのバージョンを指定することもできますが、代わりにエイリアスを指定することもできます。
以下のエイリアスがあります。
DEFAULT: デフォルトのバージョンFIRST: 作成日時で一番古いバージョンLAST: 作成日時で一番新しいバージョン
例えばLASTエイリアスは、日次でモデルを更新している際に常に最新のバージョンのモデルを利用するユースケースが想定できます。
DEFAULTエイリアスは、新しいモデルを作成した際に、すぐに切り替えるのではなく導入に向けたテストを追加でした後にエイリアスの切り替えをしてリリースするというユースケースで使えそうです。
使い方を確認する
0. データの準備
以下の『Intro to Machine Learning with Snowpark ML』の内容を参考に、DIAMONDSテーブルを用意しました。
※ クイックスタートの更新によりリンクが切れている場合は、GETTING STARTED WITH SNOWFLAKEから検索してください。
実行環境はNotebooksを使用しました。snowflake-ml-pythonは1.6.3を使用しました。
1. パイプラインの定義とトレーニング
登録済みのDIAMONDSテーブルから以下のようにパイプラインをトレーニングしました。
少し長めのコードになっていますが、ポイントは"Modeling APIのパイプラインを既存のデータで訓練した"という点のみで、ここでは内容を理解する必要はありません。このパイプラインを次のステップでレジストリに登録してエイリアスを検証します。
import pandas as pd
import numpy as np
from snowflake.snowpark.context import get_active_session
session = get_active_session()
import snowflake.ml.modeling.preprocessing as snowml
from snowflake.ml.modeling.pipeline import Pipeline
from snowflake.ml.modeling.model_selection import GridSearchCV
from snowflake.ml.modeling.xgboost import XGBRegressor
# Snowflakeのテーブルからのデータの取得
# sessionはあらかじめ作成しておく
DEMO_TABLE = 'DIAMONDS'
input_tbl = f"{session.get_current_database()}.{session.get_current_schema()}.{DEMO_TABLE}"
diamonds_df = session.table(input_tbl)
# データセットの分割
diamonds_train_df, diamonds_test_df = diamonds_df.random_split(weights=[0.9, 0.1], seed=0)
# 前処理・学習・推論のためのカラム定義
CATEGORICAL_COLUMNS = ["CUT", "COLOR", "CLARITY"]
CATEGORICAL_COLUMNS_OE = ["CUT_OE", "COLOR_OE", "CLARITY_OE"]
NUMERICAL_COLUMNS = ["CARAT", "DEPTH", "TABLE_PCT", "X", "Y", "Z"]
categories = {
"CUT": np.array(["Ideal", "Premium", "Very Good", "Good", "Fair"]),
"CLARITY": np.array(["IF", "VVS1", "VVS2", "VS1", "VS2", "SI1", "SI2", "I1", "I2", "I3"]),
"COLOR": np.array(['D', 'E', 'F', 'G', 'H', 'I', 'J']),
}
LABEL_COLUMNS = ['PRICE']
OUTPUT_COLUMNS = ['PREDICTED_PRICE']
# 機械学習パイプラインの定義
pipeline = Pipeline(
steps=[
(
"OE",
snowml.OrdinalEncoder(
input_cols=CATEGORICAL_COLUMNS,
output_cols=CATEGORICAL_COLUMNS_OE,
categories=categories,
)
),
(
"MMS",
snowml.MinMaxScaler(
clip=True,
input_cols=NUMERICAL_COLUMNS,
output_cols=NUMERICAL_COLUMNS,
)
),
(
"GridSearchCV",
GridSearchCV(
estimator=XGBRegressor(random_state=42),
param_grid={
"n_estimators":[300, 400],
"learning_rate":[0.1, 0.2],
},
n_jobs = -1,
scoring="neg_mean_squared_error",
input_cols=CATEGORICAL_COLUMNS_OE+NUMERICAL_COLUMNS,
label_cols=LABEL_COLUMNS,
output_cols=OUTPUT_COLUMNS
)
)
]
)
# モデルのトレーニング
pipeline.fit(diamonds_train_df)
2. モデルのレジストリへの登録
ここからが本題になります。以下のようにパイプラインをV_1とV_2の2つのバージョンでModel Registryに登録しました。
from snowflake.ml.registry import Registry
reg = Registry(session=session)
# V_1の登録
reg.log_model(
model_name="diamond_xgboost_regressor",
version_name="V_1",
model=pipeline,
comment="version 1"
)
# V_2の登録
reg.log_model(
model_name="diamond_xgboost_regressor",
version_name="V_2",
model=pipeline,
comment="version 2"
)
SQLワークシートで登録したモデルを確認すると、以下のようにエイリアスがついていることが確認できました。
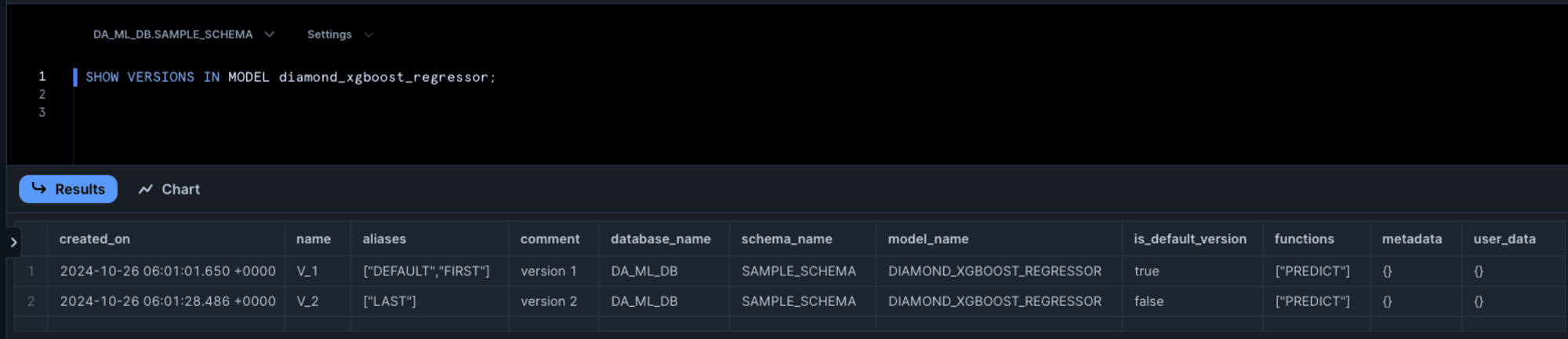
V_1にはDEFALTとFIRST、V_2にはLASTが付いています。
3. エイリアスを指定してモデルを利用する
今回はLASTに興味があるので、PythonとSQLでこのエイリアスのバージョンを使用する方法を確認します。
まずはPythonでの利用の仕方をNotebooksから確認しました。
m = reg.get_model("diamond_xgboost_regressor")
mv = m.version("LAST")
print(mv.comment)
# version 2
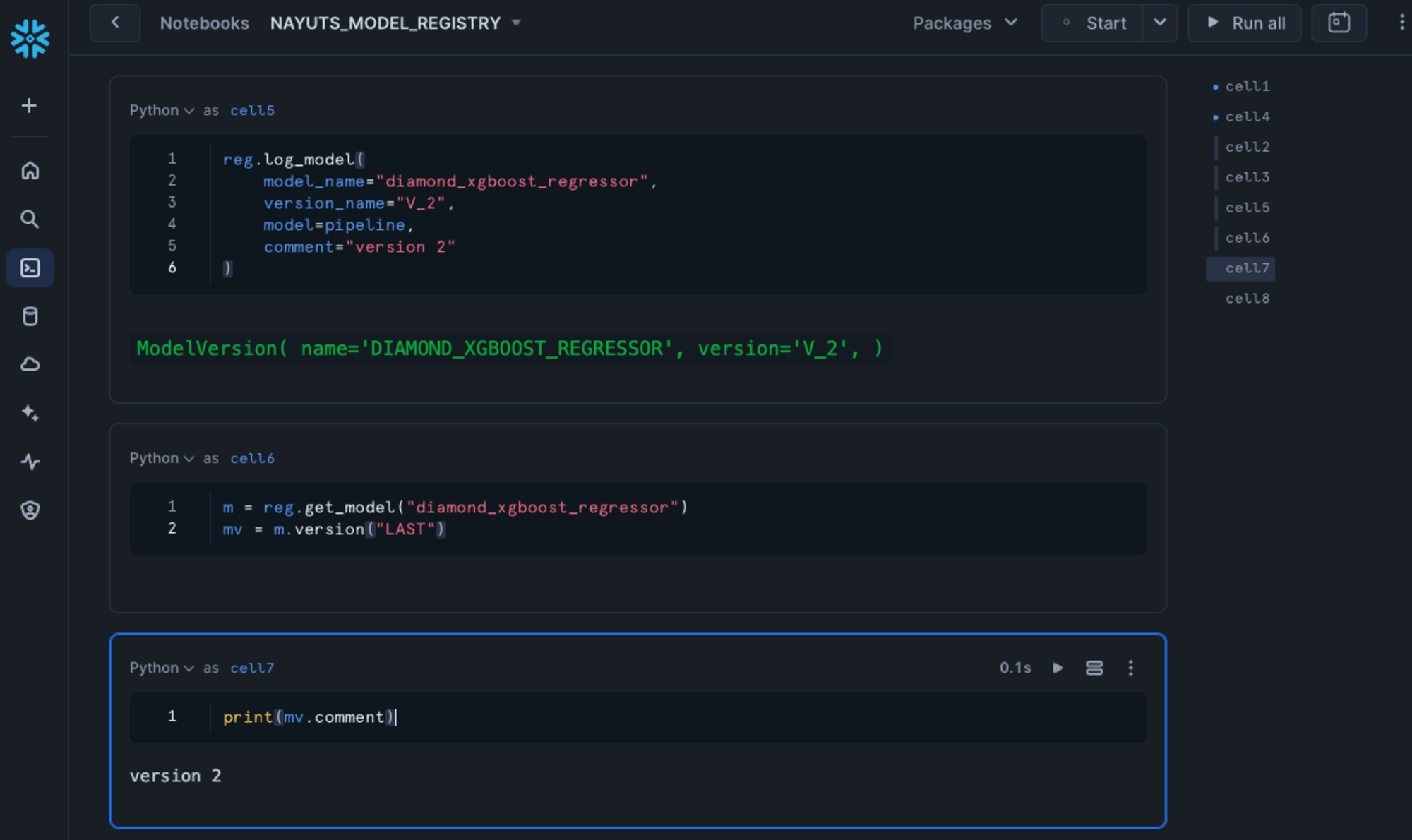
バージョンが分かるようにコメントをバージョン作成時に付与していましたが、確かにV_2が使えていることを確認できました。
SQLはWITH句を使ってエイリアスを指定することができました。
WITH LATEST AS MODEL DIAMOND_XGBOOST_REGRESSOR VERSION LAST
SELECT LATEST!PREDICT(*):PREDICTED_PRICE::FLOAT AS PREDICTED_PRICE
FROM
(
SELECT * EXCLUDE PRICE
FROM DIAMONDS
LIMIT 10
);
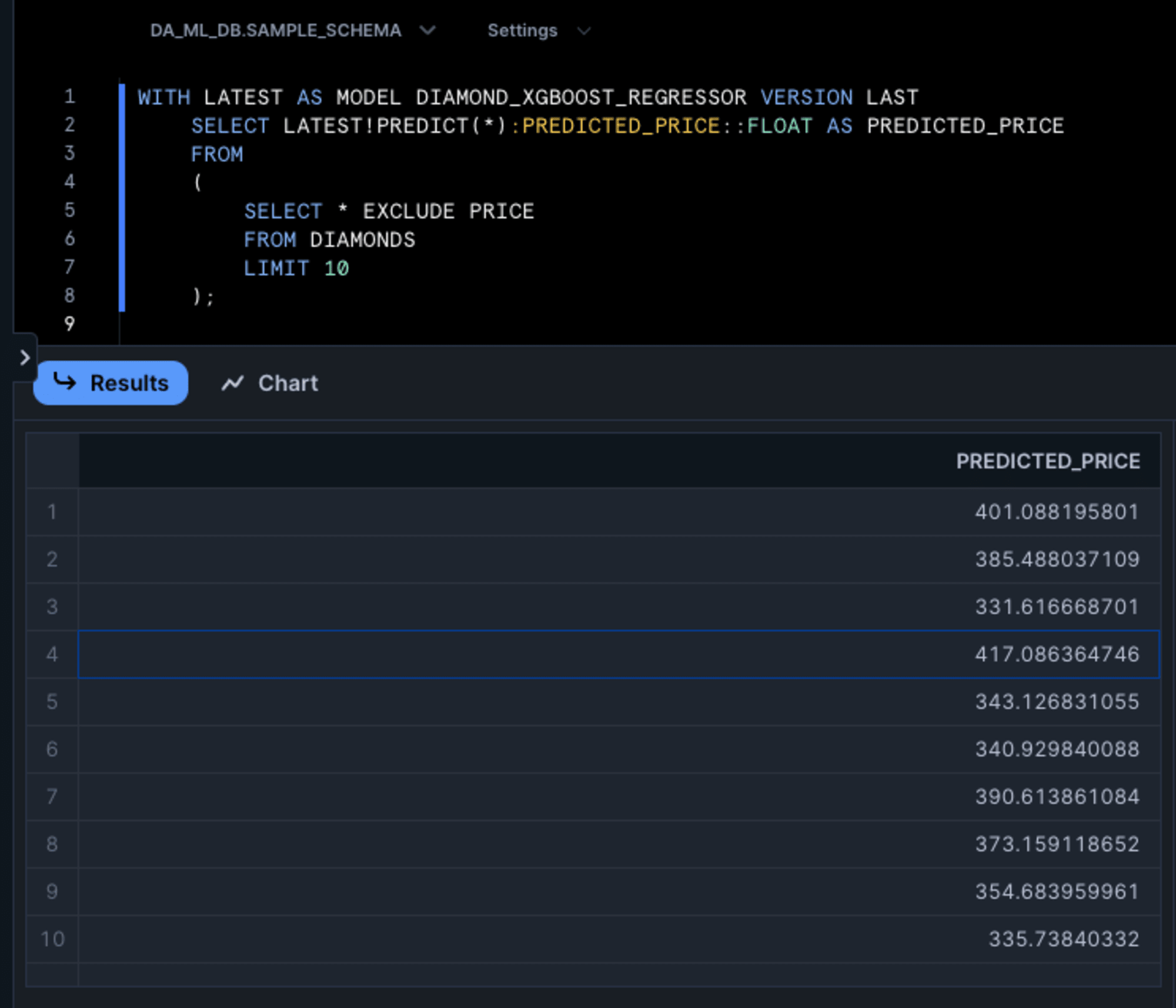
この利用方法は以下のガイドに紹介されています。
最後に
LASTエイリアスに注目して、Snowpark ML Model Registryのモデルバージョンのエイリアスについてご紹介しました。
簡単な機能ですが、これがあるとモデルの利用の実装が大幅に簡潔になるため非常に大事な要素になります。
参考になりましたら幸いです。







